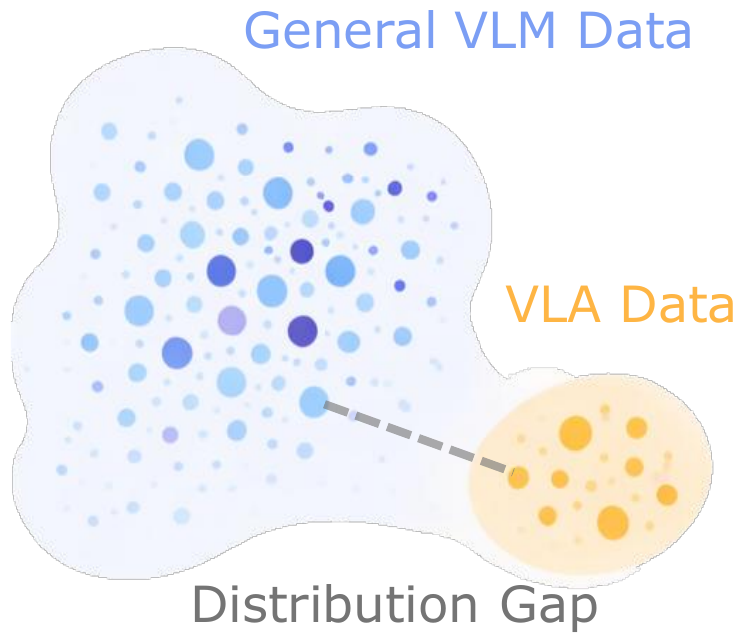
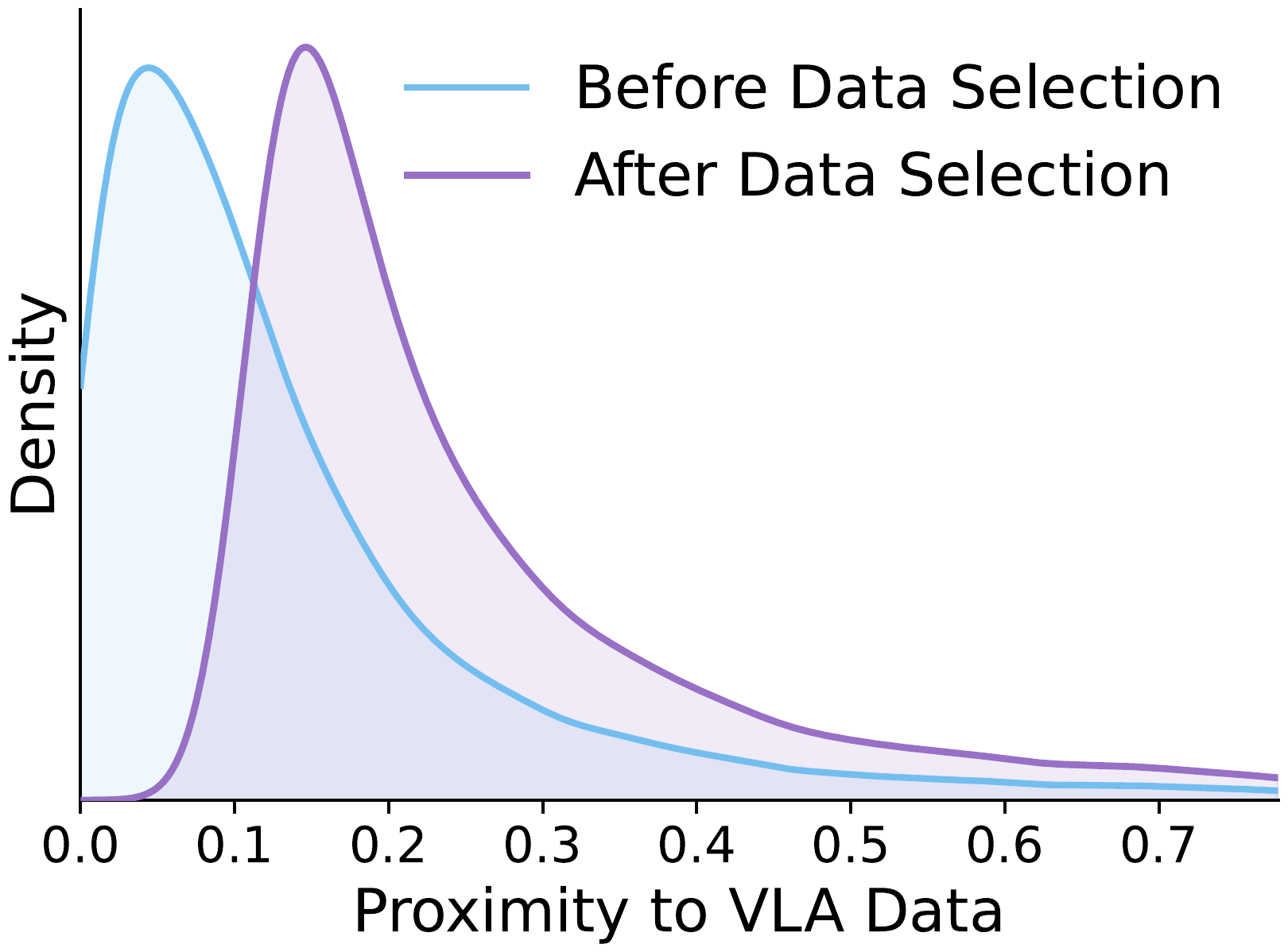
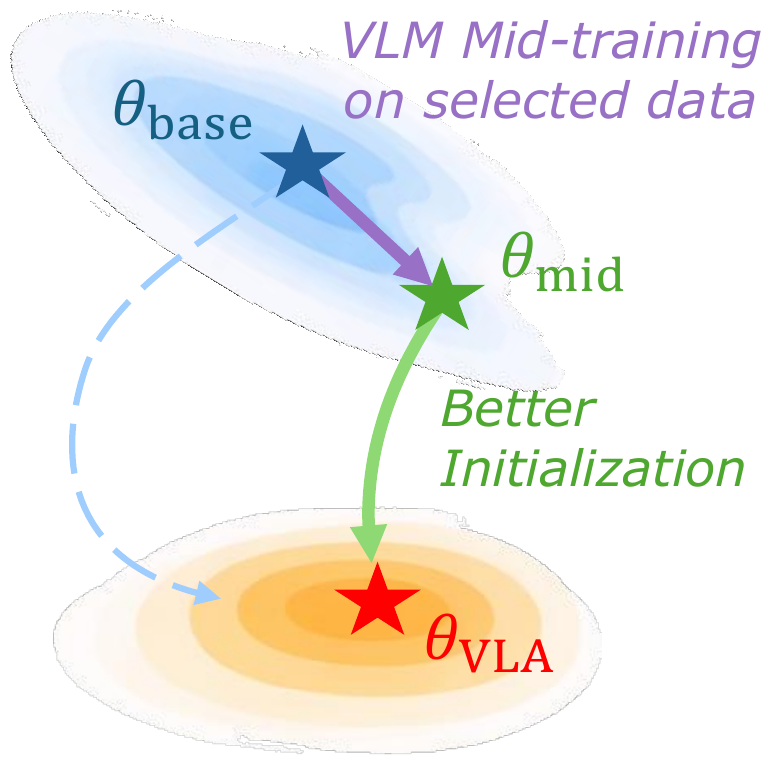
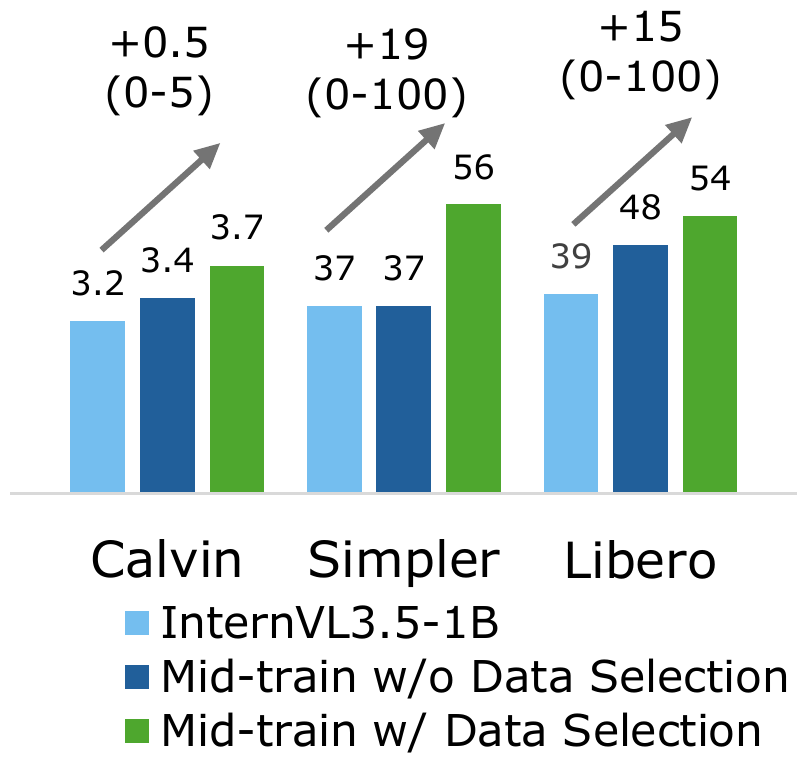
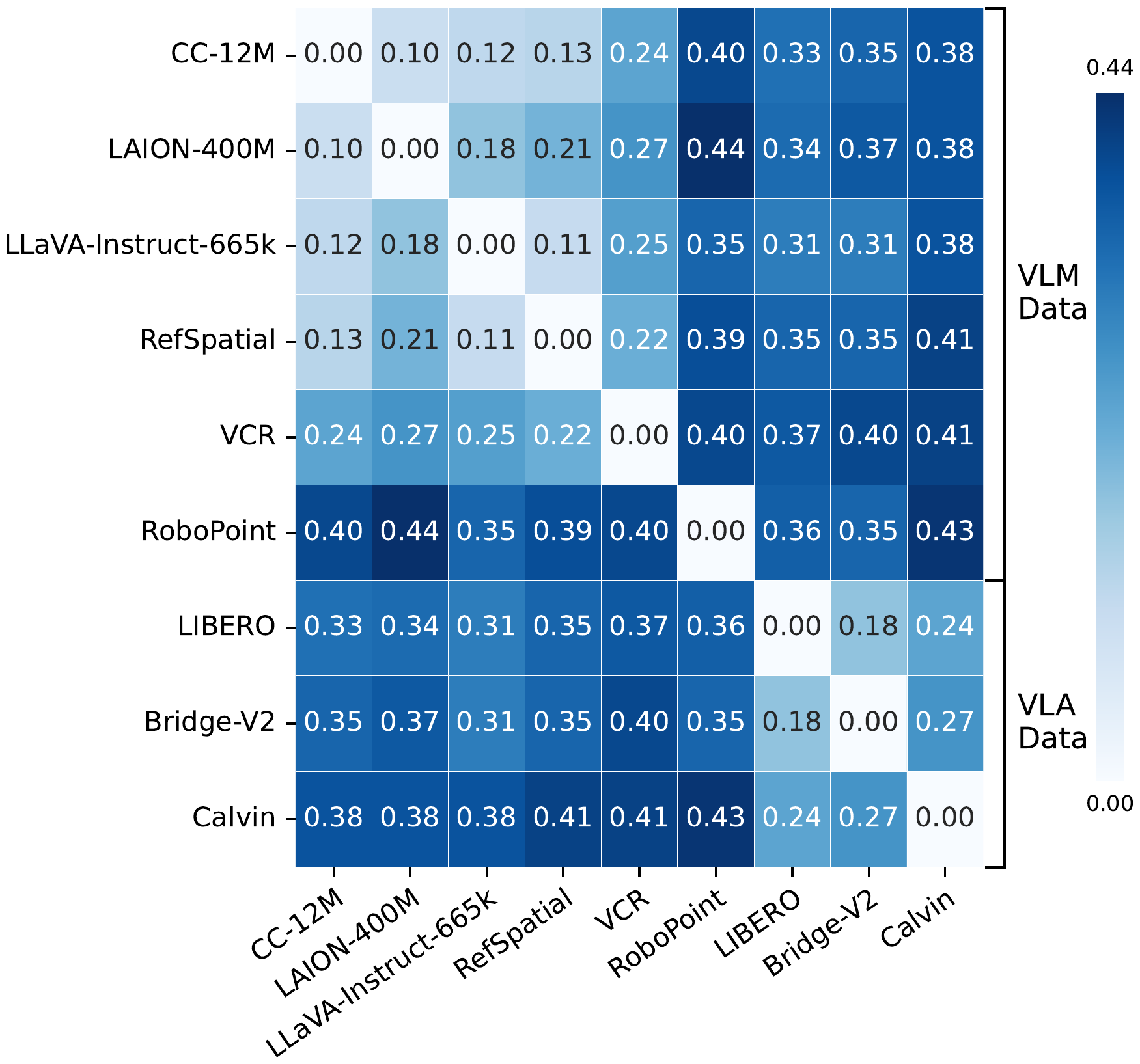
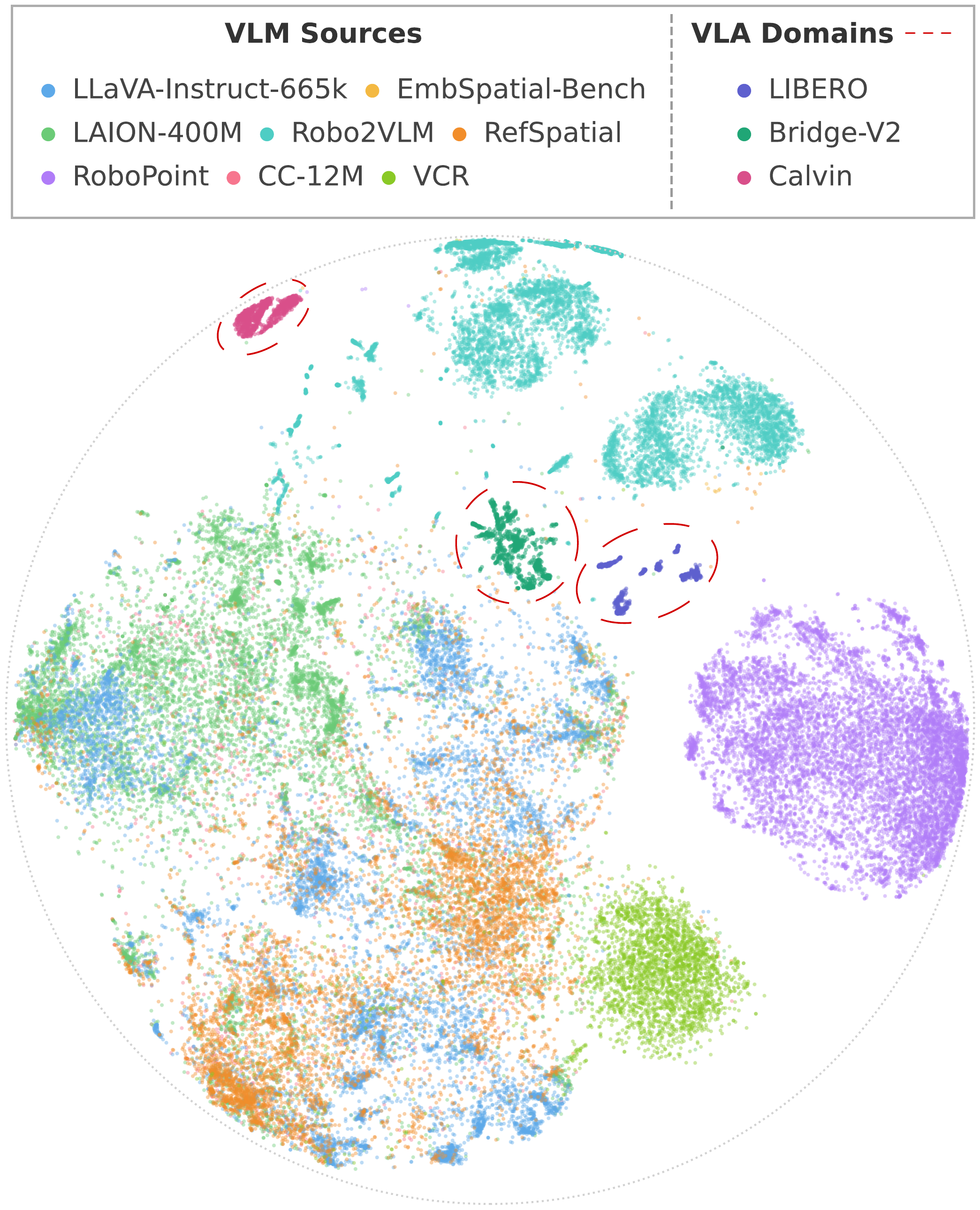
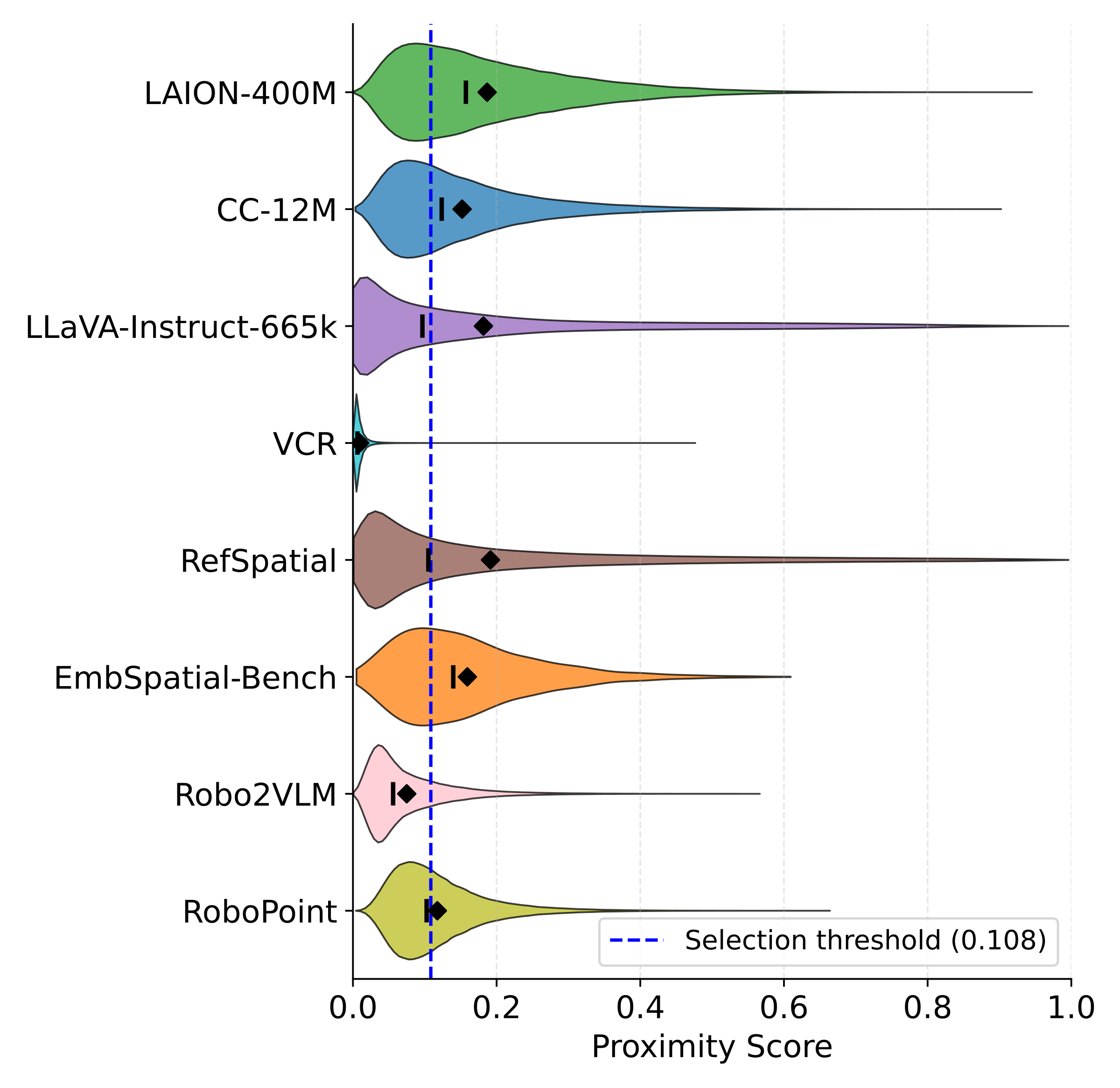
We propose a mid-training data engine that selects VLM samples whose distribution best aligns with the VLA domain. The data mixture spans both general and embodied-oriented VLM sources to preserve diversity, and selection operates at the sample level rather than the dataset level.
Proximity-Based Data Selection
Let $\mathcal{D}_{\mathrm{VLM}}$ and $\mathcal{D}_{\mathrm{VLA}}$ denote the candidate VLM pool and target VLA corpus, with densities $p_{\mathrm{VLM}}$ and $p_{\mathrm{VLA}}$ over a shared representation space. Our goal is to select a size-$K$ subset whose distribution best aligns with VLA data:
$\mathcal{D}_{\mathrm{VLM}}^{*} = \underset{\mathcal{D}' \subseteq \mathcal{D}_{\mathrm{VLM}},\; |\mathcal{D}'| = K}{\operatorname{argmin}} \; d(P_{\mathcal{D}'},\; P_{\mathrm{VLA}})$
where $d$ is a distributional divergence. Solving this exactly is intractable, so we relax it to per-sample scoring and top-$K$ selection: $\mathcal{D}_{\mathrm{VLM}}^{*} = \operatorname{top\text{-}K}_{x_i \in \mathcal{D}_{\mathrm{VLM}}} s(x_i)$. The key question is how to define the scoring function $s$. A natural choice is the density ratio $p_{\mathrm{VLA}}(x)/p_{\mathrm{VLM}}(x)$, but estimating this directly in high-dimensional feature spaces is difficult. We instead leverage a classical result from density ratio estimation: a binary classifier trained to distinguish two distributions recovers this ratio at optimality:
$s^{*}(x) = \dfrac{p_{\mathrm{VLA}}(x)}{p_{\mathrm{VLA}}(x) + p_{\mathrm{VLM}}(x)}$
Since $s^{*}$ is monotonically increasing in the density ratio, ranking by the classifier output is equivalent to ranking by the density ratio.
Proximity Estimator
We instantiate this as a lightweight proximity estimator on frozen VLM features. The estimator applies a learnable scoring function $f$ on top of the frozen VLM's last hidden state $\phi(\mathbf{x})$, followed by a sigmoid:
$s(\mathbf{x}) = \sigma\!\big(f(\phi(\mathbf{x}))\big)$
We train with VLA samples as positives and VLM samples as negatives, using binary cross-entropy loss:
$\mathcal{L}_{\mathrm{cls}} = -\mathbb{E}_{y \sim \mathcal{D}_{\mathrm{VLA}}} [\log s(y)] - \mathbb{E}_{x \sim \mathcal{D}_{\mathrm{VLM}}} [\log (1-s(x))]$
After training, we rank all candidate VLM samples by $s(x)$ and retain the top-$K$ to form $\mathcal{D}_{\mathrm{VLM}}^{*}$ for mid-training. This procedure turns a broad candidate pool into a more targeted corpus for embodied adaptation, preserving the useful diversity of VLM data while shifting the training distribution toward the VLA domain.